Introduction to Data Lakes and Data Warehouses

Introduction
- Businesses generate vast amounts of data from various sources.
- Understanding Data Lakes and Data Warehouses is crucial for effective data management.
- This blog explores differences, use cases, and when to choose each approach.
1. What is a Data Lake?
- A data lake is a centralized repository that stores structured, semi-structured, and unstructured data.
- Stores raw data without predefined schema.
- Supports big data processing and real-time analytics.
1.1 Key Features of Data Lakes
- Scalability: Can store vast amounts of data.
- Flexibility: Supports multiple data types (JSON, CSV, images, videos).
- Cost-effective: Uses low-cost storage solutions.
- Supports Advanced Analytics: Enables machine learning and AI applications.
1.2 Technologies Used in Data Lakes
- Cloud-based solutions: AWS S3, Azure Data Lake Storage, Google Cloud Storage.
- Processing engines: Apache Spark, Hadoop, Databricks.
- Query engines: Presto, Trino, Amazon Athena.
1.3 Data Lake Use Cases
✅ Machine Learning & AI: Data scientists can process raw data for model training.
✅ IoT & Sensor Data Processing: Real-time storage and analysis of IoT device data.
✅ Log Analytics: Storing and analyzing logs from applications and systems.
2. What is a Data Warehouse?
- A data warehouse is a structured repository optimized for querying and reporting.
- Uses schema-on-write (structured data stored in predefined schemas).
- Designed for business intelligence (BI) and analytics.
2.1 Key Features of Data Warehouses
- Optimized for Queries: Structured format ensures faster analysis.
- Supports Business Intelligence: Designed for dashboards and reporting.
- ETL Process: Data is transformed before loading.
- High Performance: Uses indexing and partitioning for fast queries.
2.2 Technologies Used in Data Warehouses
- Cloud-based solutions: Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse.
- Traditional databases: Teradata, Oracle Exadata.
- ETL Tools: Apache Nifi, AWS Glue, Talend.
✅ Enterprise Reporting: Analyzing sales, finance, and marketing data.
✅ Fraud Detection: Banks use structured data to detect anomalies.
✅ Customer Segmentation: Retailers analyze customer behavior for personalized marketing.
3. Key Differences Between Data Lakes and Data Warehouses
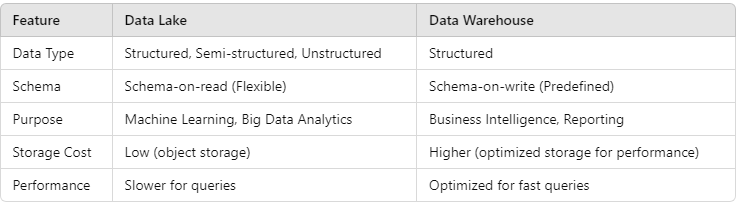
4. Choosing Between a Data Lake and Data Warehouse
Use a Data Lake When:
- You have raw, unstructured, or semi-structured data.
- You need machine learning, IoT, or big data analytics.
- You want low-cost, scalable storage.
Use a Data Warehouse When:
- You need fast queries and structured data.
- Your focus is on business intelligence (BI) and reporting.
- You require data governance and compliance.
5. The Modern Approach: Data Lakehouse
- Combines benefits of Data Lakes and Data Warehouses.
- Provides structured querying with flexible storage.
- Popular solutions: Databricks Lakehouse, Snowflake, Apache Iceberg.
Conclusion
- Data Lakes are best for raw data and big data analytics.
- Data Warehouses are ideal for structured data and business reporting.
- Hybrid solutions (Lakehouses) are emerging to bridge the gap.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/



Comments
Post a Comment